

Some people have asked us how we are going to write our compiler, and if that is not very complicated.
The honest answer to that question is that it is indeed very complicated, but we use tools to help us doing it, which makes it a little bit easier.
In my previous blog article I have described how we are using the Roslyn infrastructure for a large part of our compiler, and that “all” we have to do is to create a recognizer for our language.
In this article I would like to elaborate a little bit about the language recognition part.
Antlr
For our language recognition we are using a tool called ANTLR (Another Tool for Language Recognition), written by Terence Parr, a professor from the University of San Fransisco.
This tool allows us to generate a major part of the language recognizer from language definition files. This language definition roughly consist of 2 elements:
- Tokens. These are the sequences of characters that form the Keywords, Identifiers, Constants (Strings, Integers, Floats, Symbols etc.) comments and whitespace in our language.
- Rules. These are the sequences of tokens that form our language.
From this definition the Antlr tool generates classes:
- A Lexer class that scans the source code and builds a list of tokens (the tokenstream)
- A Parser class that uses the rules and scans for the patterns from the language elements. This builds the Parse Tree.
Token definitions for the Lexer
ACCESS : A C C E S S
| {_Four}? A C C E (S)?
;
ALIGN : A L I G N
|{_Four}? A L I G
;
AS : A S ;
ASSIGN : A S S I G N
| {_Four}? A S S I (G)?
.
.
STRING_CONST: '"' ( ~( '"' | '\n' | '\r' ) )* '"'
;
.
.
fragment A : 'a' | 'A';
fragment B : 'b' | 'B';
As you can see the tokens are defined as a series of characters.Each character itself in the defintion actually represents both the upper case and the lower case version of the character (which makes the keywords case insensitive).
Some tokens have multiple definitions, possibly using wildcards. These extra definitions are there for the tokens that may be abbreviated to 4 characters as is common in most xBase languages.
The question marks indicate optional characters. We have separated the abbreviated defintions and put a logical condition (predicate) in front of them so we can enable/disable these abbreviations at a central location.
The STRING_CONST token shows that we can use wild cards and OR operators. A String Constant in this defition is a double quote followed by any number of characters that is not a double quote, CR or LF and terminated with a double quote.
Rule definitions for the Parser
function : (Modifiers+=funcprocmodifier)*
FUNCTION Id=identifier
(ParamList=parameterList )?
(AS Type=datatype)?
(CallingConvention=callingconvention)? eos
StmtBlk=statementBlock
;
The parser rule above defines the function rule. It specifies that a function consists of an optional list(*) of Modifiers (STATIC, PUBLIC, INTERNAL etc) followed by a FUNCTION keyword, followed by an identifier and an optional(?) parameter list, an optional(?) result type, an optional Callingconvention(?) and finally an End of Statement (NewLine) followed by a statementBlock, which is a list of statements.
These defintions are often also shown as diagrams such as the ones below:
|
|
|
|
|
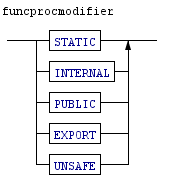
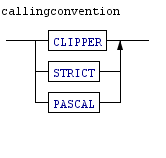
All in all this can become quite complex. The current definition files of X# are a Token definition of 550 lines and a rule definition of more than 700 lines, and we are not there yet.
From these definitions ANTLR will generate source code. This source code is quite easy to read. For example the function rule above results in the following source code:
public FunctionContext function() {
FunctionContext _localctx = new FunctionContext(Context, State);
EnterRule(_localctx, 4, RULE_function);
int _la;
try {
EnterOuterAlt(_localctx, 1);
{
State = 239;
ErrorHandler.Sync(this);
_la = TokenStream.La(1);
while ((((_la) & ~0x3f) == 0 && ((1L << _la) & ((1L << EXPORT) | (1L << PUBLIC) | (1L << STATIC))) != 0) || _la==INTERNAL || _la==UNSAFE) {
{
{
State = 236; _localctx._funcprocmodifier = funcprocmodifier();
_localctx._Modifiers.Add(_localctx._funcprocmodifier);
}
}
State = 241;
ErrorHandler.Sync(this);
_la = TokenStream.La(1);
}
State = 242; Match(FUNCTION);
State = 243; _localctx.Id = identifier();
State = 245;
_la = TokenStream.La(1);
if (_la==LPAREN) {
{
State = 244; _localctx.ParamList = parameterList();
}
}
State = 249;
_la = TokenStream.La(1);
if (_la==AS) {
{
State = 247; Match(AS);
State = 248; _localctx.Type = datatype();
}
}
State = 252;
_la = TokenStream.La(1);
if ((((_la) & ~0x3f) == 0 && ((1L << _la) & ((1L << CLIPPER) | (1L << PASCAL) | (1L << STRICT))) != 0)) {
{
State = 251; _localctx.CallingConvention = callingconvention();
}
}
State = 254; eos();
State = 255; _localctx.StmtBlk = statementBlock();
}
}
catch (RecognitionException re) {
_localctx.exception = re;
ErrorHandler.ReportError(this, re);
ErrorHandler.Recover(this, re);
}
finally {
ExitRule();
}
return _localctx;
}
As you can see this code is quite easy to read. TokenStream.La(1) looks 1 token ahead in the stream of tokens produced by the Lexer.
What's next
For the X# compiler the generated parse tree is an intermediate step in the compilation process. This parse tree is inspected using a (hand written) tree walker which helps to generate a Tree structure that the Roslyn system understands. From there we can then use the complete Roslyn infrastructure to do read Metadata, do Symbol Lookups, bind our tree to the imported types and then finally generate IL code.
How this is done exactly is outside of the scope of this article.
I hope this has helped you to form an idea of how our language recognizer works.