

Introduction
We have been quite busy creating the X# runtime. And when we did that we stumbled on the problem of bytes, characters, codepages, Ansi and Unicode. X# has to deal with all of that and that can become quite complicated. That is why we decided to write a blob post about this. In this post we look back to explain the problems from the past and how the solutions to these problems are still relevant for us in a Unicode XBase environment such as X#.
Bytes and Characters in DOS
When IBM introduced Dos in the 80's the computing world was much less complex than it is right now. Computers were rarely connected with a network and certainly not with computers outside the same office building or even outside the same city or country. Nowadays all our computers are connected through the internet and that brings new challenges for handling multiple languages with different character sets.
The origin of the XBase language was in CP/M (even before DOS) and the XBase runtimes and fileformats have evolved over time taking into account these changes.
Before IBM sold computers they were big in the typewriter industry. So they were well aware that there are different languages in the world with different character sets. Their IBM typewriters came in different versions with a different keyboard layout and different "ball" with characters. There were different balls with different character sets and different balls with fonts (Courier and Prestige were the most used, with 10 and 12 characters per inch).
DOS used a single byte (8 bits) to represent characters. So there was a limited number of characters available. The number was certainly not big enough to represent all characters used by languages for which IBM was developing computers.
That is why IBM decided to group characters in so called Code Pages. The most common codepage used in the US and many other countries in the world was code page 437.
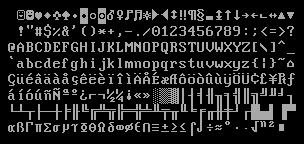
Code page 437
This codepage contains all non-accented Latin characters as well as several characters with accents, several (but not all) Greek characters, the inverted exclamation mark and question mark used in Spanish and quite some line draw characters, used to draw different boxes on the 25 x 80 DOS displays.
Unfortunately this was not enough.
For many western European languages accented and special characters were missing, so for these countries the codepage 850 was used.

Code page 850
If you compare this codepage with 437 you will see that the first half (0-127) are identical. The top half contains some differences.
As developer you had to be aware of the codepage your client was using, because sometimes the carefully crafted boxes looked terrible if a customer was using codepage 850. A linedraw character would be replaced with an accented character :(.
Outside western europe this still was not enough. My Greek colleagues could not work with codepage 850 because many Greek characters are missing.
Several Greek codepages were invented, such as codepage 851. The last one that I know about is codepage 737

Code page 737
And on other platforms (such as main frames, apple computers, unix etc) there are also codepages. Wikipedia has a page full just with the list of codepages: https://en.wikipedia.org/wiki/Code_page. And sometimes the same code page has different names, depending on who you talked with <g>.
The reason that I am bringing this up now, 40 years later, is that this was the situation in which XBase was born and in which the first Clipper programs were running. DBFs created with Clipper would store 8 bit characters in files and the active code page on the machine that the application was running on would give these characters a meaning. So the same byte 130 in a file would be represented as an accented E (é ) on a machine with codepage 437 or 850, but as a capital Gamma (Γ) on a Greek computer running codepage 737.
So there is a difference between bytes and characters, even in the DOS world.
The codepage gives the byte a "meaning". The byte itself has no meaning. There is a 'contract' that says that the number 65 in a field with a string value is the character 'A'. But in reality it is just a number.
And why are the lower case characters exactly 32 positions later in the table as the uppercase characters? That was simply convenient so with a simple AND or OR operation characters could be converted to upper or lower case.
Sorting
Also some rules had to be established on how to sort these characters and how to convert characters from uppercase to lowercase. DOS did not have built-in support for sorting characters, so each developer had to create his own routine. Clipper used so called nation modules (ntxfin.obj for Finnish, ntxgr851.obj for Greek with codepage 851 etc.) . Each of these modules contained 3 tables: a table to convert lowercase to uppercase, a table for the uppercase to lowercase and finally a table that defines the relative sort weight for each character. This last table could position the accented 'é' (130) between 'e' and 'f' for example by giving it a weight greater than 'e' and smaller than 'f'. But of course for Greek in codepage 737 that would be completely useless since 130 then represents the Capital Gamma (Γ). Even between 2 Greek codepages there could be complications. The original Greek codepage 851 had the capital Gamma at 166 where codepage 737 put it at the location 130.
Anyway this all worked, as long as you used one machine or one network with machines with the same setup.
Moving from DOS to Windows
And then Windows came and we started to use Visual Objects.
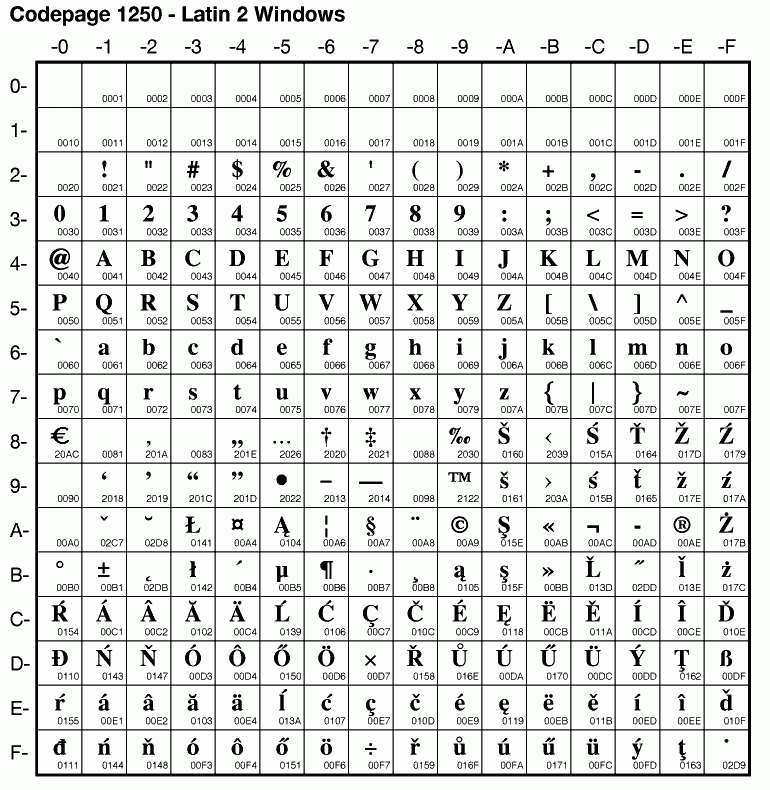
Microsoft decided that Windows would be using again different codepages. So they introduced the distinction between OEM Codepages and ANSI codepages. The original 437, 850 etc. were labeled as OEM codepages. Microsoft introduced new windows codepages such as 1252 (ANSI Latin ) and 1253 (ANSI Greek).
The biggest change compared to the original codepages in DOS was that the line draw characters were no longer there, which makes sense because they were no longer needed in a graphical user interface, and these line draw characters were replaced by accented characters. As a result several national codepages could be merged in regional codepages. The lower half of all codepages was still the same as in DOS, and most differences were in the upper half.
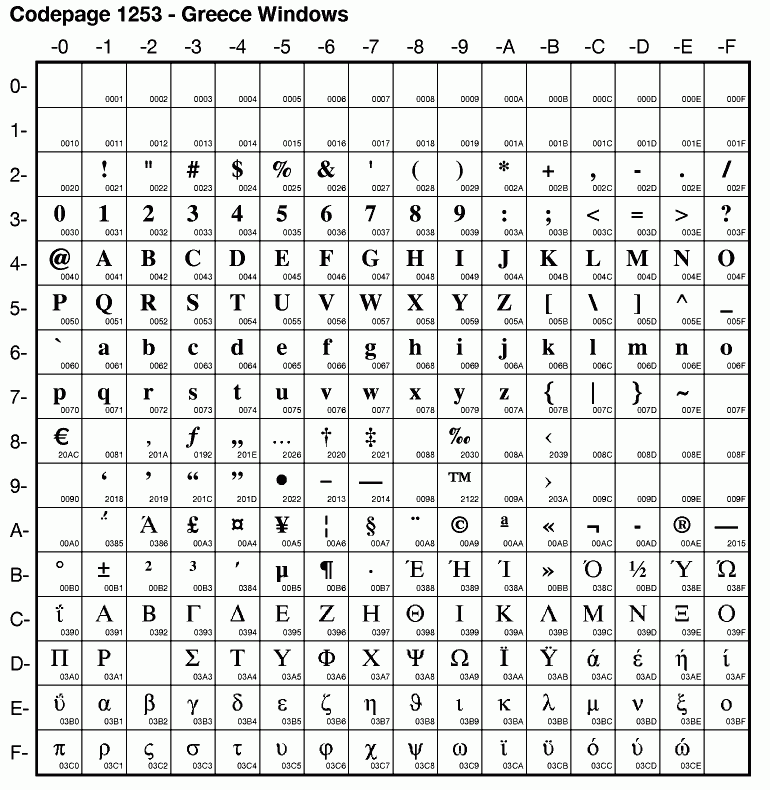
There are again really some changes. The Gamma has been moved to 0xC3 = 195.
This was a challenge of course for the original developers of Visual Objects. They had to deal with 'old' data files and text files created in DOS and 'new' data files created in Windows.
Ansi and OEM in Visual Objects
One of the things introduced in the language to solve this was the ANSI setting of the Visual Objects language.
With SetAnsi(TRUE) you were telling the runtime that you wanted to run in 'Ansi' mode and that any files you create should be written in Ansi format.
With SetAnsi(FALSE) you told the VO runtime that you want to work in OEM mode.
The major area affected by this was the DBF access. There are a couple of possible scenarios:
- Reading a DBF file created in a Clipper application.
This file has a marker in the header with the value 0x03 or 0x83 indicating DBF without memo or with memo. The 0x03 also indicates that the file is in OEM format. When the SetAnsi setting in VO is true then VO will call a Windows function OemToChar when reading data and will call CharToOEM when writing data. As a result characters are mapped from the location in the DOS codepage to the windows codepage. With SetAnsi(FALSE) no translation is done. So the strings in memory will have the same binary values as the strings in the file.
- DBF files created in VO with SetAnsi(FALSE) will have the same 0x03 and 0x83 header bytes and will be compatible with DBF files created in Clipper.
- DBF files created in VO with SetAnsi(TRUE) will have a header byte 0x07 or 0x87, so one bit with the value 0x04 is set. This bit indicates that the file is Ansi encoded and no OEM translation will be done.
Important to realize is that the SetAnsi() flag is global and that mixing files with different settings will most likely cause problems.
Sorting in Visual Objects
For string comparisons VO introduced the so called Collation. With SetCollation(#Clipper) you can tell the runtime that you want Clipper compatible comparisons. VO uses Nation DLLs for this. These Nation DLLs contain the same tables that the original Clipper nation modules had. So if you app contained the code SetNationDLL("Pol852.dll") and SetCollation(#Clipper) then the strings would be sorted according to the Polish collation rules for codepage 852.
One potential problem when reading OEM files is that the Oem2Ansi and Ansi2OEM functions in windows do not allow you to specify which OEM codepage you want to convert to. The ANSI codepage is the codepage that matches the current Windows version. The OEM Codepage is a global setting in windows that is difficult to see and control. If you want to see what the OEM setting on your machine is, then the easiest way to do so is to open a command prompt and type CHCP. This should show the active OEM codepage.
When you work with Ansi files you are most likely better off by using the default SetCollation(#Windows). This will sort indexes using the built-in sorting routines from windows.
Unfortunately that is not enough in some scenarios. Especially in countries where more than language of windows is spoken and when different users can have different language versions of windows. The reason for that is that these different language versions of windows can have different sorting algorithms.
When SetCollation(#Windows) is used then Visual Objects uses a built in windows function to sort. This function takes a localeID as parameter which indicates how to sort.
Visual Objects 2.8 introduced a runtime function that allows you to specify this localeID in code, so you can make sure that every program running your code uses the same locale. For example
to use the standard German Language in Phone Book sorting mode:
SetAppLocaleId(MAKELCID(MAKELANGID(LANG_GERMAN, SUBLANG_GERMAN),;
SORT_GERMAN_PHONE_BOOK))
to use the Swiss German Language in Default sorting mode:
SetAppLocaleId(MAKELCID(MAKELANGID(LANG_GERMAN, SUBLANG_GERMAN_SWISS),;
SORT_DEFAULT))
to use the Norwegian Bokmal language, default sorting mode:
SetAppLocaleId(MAKELCID(MAKELANGID(LANG_NORWEGIAN,SUBLANG_NORWEGIAN_BOKMAL),;
SORT_DEFAULT))
// To use language independent sorting
SetAppLocaleId(MAKELCID(MAKELANGID(LANG_NEUTRAL,SUBLANG_NEUTRAL), ;
SORT_DEFAULT))
With all these tools in place your VO app could both read and write Clipper files and also read and write files with Windows/Ansi encoding.
Single byte Ansi and Multi Byte Ansi
Since the character sets were based on 8 bit characters there was a problem with languages with more characters(or symbols), such as Chinese, Korean and Japanese.
For these languages the so called Double Byte Character Sets (DBCS) were introduced. These are character sets where some characters are represented by 2 bytes.
The mechanism behind all of this actually quite complex, but the simple version is that some characters in the upper half of the character set are like 'doors' into a second page of 256 characters. This actually works great and windows supports all of that.
The top half of the characters (everything upto 127) is a "normal character". The bottom half contains characters that act like a doorway to a table of the 'real characters'. These are called the leadbytes.
The unicode website shows you how this works: http://demo.icu-project.org/icu-bin/convexp?conv=windows-936
If you click on the lead byte 0x81 in the codepage you will skip to the page where the characters are shown that all start with this leadbyte. So 0x8140 is the character 丂 and 0x8150 the character 丳. (I apologize if these are obscene or inappropriate characters, I really have no idea).
One of the problems from the programmers view is that you can no longer know the number of characters in a string based on the number of bytes in a string. Some characters are represented by multiple bytes.
The owner of Computer Associates was Chinese and also wanted to prepare Visual Objects for the Chine market (the project was called Wen Deng)
This is why the Visual Objects runtime was extended with functions like MBLen() and MBAt(). These functions return character positions or character lengths and no longer byte positions and byte lengths.
With the move to X# things have become easier and more complicated at the same time.
In Part 2 of this article I will explain how we are handling this inside X#.