

To cast or not to cast
- Robert van der Hulst
In our attempt to make X# as compatible as possible we are supporting almost all the constructs of the VO language. One of the language constructs that gives some problems is the _CAST operation.
Take the following code:
FUNCTION start
LOCAL uValue AS USUAL
LOCAL siValue AS SHORT
uValue := 100
siValue := SHORT(_CAST, uValue)
? uValue
? siValue
WAIT
RETURN NIL
Which result is printer for siValue and uValue ?
Most of you will answer 100, and that is correct.
What if we change the example to:
FUNCTION start
LOCAL uValue AS USUAL
LOCAL siValue AS SHORT
uValue := MyFunction()
siValue := SHORT(_CAST, uValue)
? uValue
? siValue
WAIT
RETURN NIL
FUNCTION MyFunction
RETURN 1 - PI
What will the answer be ? (And yes, PI is a predefined constant in VO and X# with the value of 3.14159265358979323846). And please, don't cheat, don't run the example in VO. Just solve this in your head.
In the previous article I have described how the xBase world evolved from DOS/Dbase and DOS/Clipper to Windows/Visual Objects and how that affected the character sets. OEM character sets for DOS/Clipper and Ansi Character sets for Windows/VO.
In this article I would like to discuss the relevance of all of this in relation to X#.
Introduction
To start: X# is a .Net development language as you all know and .Net is a Unicode environment. Each character in a Unicode environment is represented by one (or sometimes more) 16 bit numbers. The Unicode character set allows to encode all known characters, so your program can display any combination of West European, East European, Asian, Arabic etc. characters. At least when you choose the right font. Some fonts only support a subset of the Unicode characters, for example only Latin characters and other fonts only Chinese, Korean or Japanese.
The Unicode character set also has characters that represent the line draw characters that we know from the DOS world, and also various symbols and emoticons have a place in the Unicode character set.
Introduction
We have been quite busy creating the X# runtime. And when we did that we stumbled on the problem of bytes, characters, codepages, Ansi and Unicode. X# has to deal with all of that and that can become quite complicated. That is why we decided to write a blob post about this. In this post we look back to explain the problems from the past and how the solutions to these problems are still relevant for us in a Unicode XBase environment such as X#.
Bytes and Characters in DOS
When IBM introduced Dos in the 80's the computing world was much less complex than it is right now. Computers were rarely connected with a network and certainly not with computers outside the same office building or even outside the same city or country. Nowadays all our computers are connected through the internet and that brings new challenges for handling multiple languages with different character sets.
The origin of the XBase language was in CP/M (even before DOS) and the XBase runtimes and fileformats have evolved over time taking into account these changes.
Before IBM sold computers they were big in the typewriter industry. So they were well aware that there are different languages in the world with different character sets. Their IBM typewriters came in different versions with a different keyboard layout and different "ball" with characters. There were different balls with different character sets and different balls with fonts (Courier and Prestige were the most used, with 10 and 12 characters per inch).
DOS used a single byte (8 bits) to represent characters. So there was a limited number of characters available. The number was certainly not big enough to represent all characters used by languages for which IBM was developing computers.
That is why IBM decided to group characters in so called Code Pages. The most common codepage used in the US and many other countries in the world was code page 437.
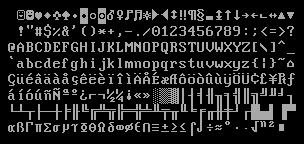
Code page 437
This codepage contains all non-accented Latin characters as well as several characters with accents, several (but not all) Greek characters, the inverted exclamation mark and question mark used in Spanish and quite some line draw characters, used to draw different boxes on the 25 x 80 DOS displays.
Background information about the X# Runtime
- Robert van der Hulst
When we designed the X# compile and X# Runtime we had a few focus points in mind:
- The language and runtime should be VO compatible whenever possible. We know that the Vulcan devteam made some decisions not to support certain features from VO, but we decided that we would like to be as compatible as technically possible.
- We want our runtime to be fully Unicode and AnyCPU. It should run on any platform and also both in x86 and x64 mode. That has caused some challenges because VO is Ansi (and not Unicode) and also X86. In VO you can cast a LONG to a PTR. That will not work in X64 mode because a LONG is 32 bits and a PTR 64 bits
- We want the code to compile in "Safe" mode. No unsafe code when not strictly needed. The biggest problem / challenge here is the PTR type. With a PTR you can access memory directly and read/write from memory, even if you don't "own" that memory. However the same PTR type is also used as "unique identifier" for example in the low level file i/o and in the GUI classes for Window and Control handles. These PTR values are never used to read/write memory but are like object references. We have decided to use the .Net IntPtr type for this kind of handles. Of course the compiler can transparently convert between PTR and IntPtr.
- We want to prove that the X# language is a first class .Net development language. That is why we decided to write the X# runtime in X#. By doing that we also create a large codebase to test the compiler. So that is a win - win situation.
- We want the runtime to be thread safe. Each thread has its own "global" state and its own list of open workareas. When a new thread is started it will inherit the state of the main thread but will not inherit the workareas from the main thread
- At this moment the X# Runtime is compiled against .Net Framework 4.6.
The XSharp Runtime
- Robert van der Hulst
At the XBase Future conference in Cologne we have presented the development roadmap. We would like to share that with you here as well.
For us 2018 is all about finishing the X# runtime.
This runtime consists of the following components:
| Component | Description |
| XSharp.Core | This is the main runtime DLL. It is written in the X# Core dialect.
|
| XSharp.VO | This is the runtime DLL that contains the support for specific things for the VO/Vulcan dialect
|
| XSharp.RDD | THis DLL contains all of the XSharp RDDs
|
| XSharp.Macrocompiler | There will be 2 macro compilers. One "Full" macro compiler and one "Fast" macro compiler. The "Full" macro compiler will be based on the Roslyn code, and is a wrapper around our scripting engine The "Fast" macro compiler is hand written and will support "just" the VO compatible macros. Both macro compilers are written in C#. |
| VO Compatible Class Libraries | The VO Class libraries that come with Visual Objects are copyright of Computer Associates. We therefore can't simply recompile them and include them with our product. Fortunately the source code to these libraries is included with every installation of VO since VO 2.5. Our solution for this is:
|
| Unicode and AnyCPU Support DLLs | The VO Compatible class libraries are based on the X86 and Ansi API calls inside windows. For some of these assemblies there is no problem using them in a Unicode and AnyCPU environment, such as:
Other assemblies will not work without significant changes in a Unicode and AnyCPU mode.
|
In the last build of X# we have introduced a small problem in some of our project templates (more about that later) and when trying to instruct one of our customers how to fix that I realized that it might be a good idea to explain our project file format a little bit.
But first let's look back at the past.
Some of us have started development in the DOS days and may remember how the build process worked in the DOS/Clipper time:
You had a folder full of source code, an RMake file with instructions on which files needed to be compiled and what the compiler commandline needed to be and a Link file with instructions on how to link the object files produced by the compiler with the standard Clipper libraries and sometimes also with 3rd party libraries.
The Rmake file contained rules that described the dependencies: The Exe file depended on a list of OBJ files, which in their turn depended on PRG and CH files. When one of the PRG or CH files was newer than the OBJ file (or the OBJ file was missing) then the compiler would be called and a new OBJ file was created. After that the linker was called because the OBJ file was newer than the EXE file.
Btw (x)Harbour uses a similar way to compile.
In part 1, part 2 and part 3 of this article series I have shown you some problems that we found in existing code (in our own code as well, and we thought that that code was perfect). Today we will discuss a few other problems that we found.
Wrong order of arguments in indexed ASSIGN in the SDK
Have you ever tried to change the caption of a tab page in a Vulcan app that uses the GUI classes with something like that? :
SELF:oDCMyTabControl:TabCaption[#MyTabPage] := "New caption"
If you have tried that, then you must have noticed that this code does not work in Vulcan (it does not work in VO either), the tab page remains unchanged! X# revealed why, it is because the TabCaption ACCESS/ASSIGN pair has been declared incorrectly in VO (and subsequently also in Vulcan):
ACCESS TabCaption(symTabName)
ASSIGN TabCaption(symTabName , cCaption) CLASS TabControl
This is an indexed ACCESS/ASSIGN, and in the ASSIGN declaration one parameter is the name (as a SYMBOL) of the tab page caption to change and the other is the new caption. But the order in which the parameters have been entered is incorrect! The first parameter should be the new value to be assigned, followed by the index expression(s). This is revealed by the X# compiler which reports:
error XS9039: The parameters for the Access and Assign declarations must match by name and type. The first ASSIGN parameter is the value, the other parameters are the indexers and must be the same as the ACCESS parameters.
So this ASSIGN should have been defined as:
ASSIGN TabCaption(cCaption , symTabName) CLASS TabControl
After making that change in the SDK code, now changing the caption of a tab page via code is working perfectly!
Weird problem with _winNMDATETIMESTRING in the VOSDK
This is by far the strangest problem we have found with the help of X#, while trying to compile the original SDK from VO. You can see it by navigating through the repo explorer of ANY version of VO to the CommCtrl module of the Win32 API Library, press CTRL+M to open all the entities of that module in the editor and search for “_winNMDATETIMESTRING”. This will point you to that chunk of code in the editor:
DEFINE DTN_USERSTRING := (DTN_FIRST + 2) // the user has entered a string
MEMBER _winNMDATETIMESTRING ALIGN 1
MEMBER nmhdr IS _winNMHDR
MEMBER pszUserString AS PSZ
MEMBER st IS _winSYSTEMTIME
MEMBER dwFlags AS DWORD
Something looks very bizarre here, doesn’t it? At least it looked bizarre to our compiler, which reported a parser error when compiling that code in X#. After a few minutes fearing that the unexpected Athens snow and cold had made our eyes “see” things that were not there, we realized what had really happened: Many, many years ago, the original authors of the VO SDK had accidentally typed “MEMBER _winNMDATETIMESTRING ALIGN 1” instead of “STRUCTURE _winNMDATETIMESTRING ALIGN 1”, causing the whole structure to get somehow embedded as part of the DEFINE DTN_USERSTRING entity above! The result of this is that the _winNMDATETIMESTRING STRUCTURE is not actually available in the SDK and this problem has been carried over also to Vulcan, where this structure is not available either. Of course this is not something of huge importance, but it was a pretty weird problem that X# revealed and I wanted to share it with you!
Typo in ShellWindow:Dispatch() of the VO SDK
This is another problem in the existing VO SDK, you can see it by opening the Dispatch() method of the ShellWindow class in the GUI Classes, again in any version of VO (or in the Vulcan SDK). In about the middle part of that entity, you will see this code:
CASE (uMsg == WM_SETCURSOR)
IF (oEvt:wParam) != (DWORD(_CAST, hwndClient))
lclient := FALSE
ELSE
lclient := TRUE
ENDIF
IF lHelpOn
IF lhelpcursorOn
lHelpEnable := TRUE
ELSE
lHelpEnable := FALSE
ENDIF
ELSE
lHelpEnable := FALSE
ENDIF
SELF:__HandlePointer(oEvt, lHelpCursorOn, lclient)
RETURN SELF:EventReturnValue
When compiling this in X#, the compiler reports: warning XS0219: The variable 'lHelpEnable' is assigned but its value is never used. That made us look more closely to the code and realize there is another typo, the 2nd argument passed to the __HandlePointer() method should be “lHelpEnable”, not “lHelpCursorOn” as it is now. So this is another thing that must be corrected in the VO SDK.
Miscellaneous potential problems revealed by X#
Most of the issues in code revealed by X# that were described above are critical ones, as in most cases they lead to serious problems when executing it at runtime. But by no means are those the only problems revealed by the compiler. X# also warns us about many other, less critical, things in our code, like inconsistent accessibility (for example when a PUBLIC method has a parameter of a type that is INTERNAL), class fields or events that are left (accidentally?) uninitialized and much more. I personally found many dozens of them when compiling XIDE in x#! Those warnings are for up to the developer to decide if he/she wants to follow the compiler’s advice to adjust the code or not. Describing all those cases would probably require a whole book, but maybe some of them could be covered in another blog article in the future.
In part 1 and part 2 of this article series I have shown you some problems that we found in existing code (in our own code as well, and we thought that that code was perfect). Today we will discuss an important other problem, that has to do with WIn32 interoperability.
Win32 Callback functions
There exist many functions in the Win32 API that require a callback function to return their results to, or use it for some other reason. Probably the most known one is the EnumWindows() function, which enumerates all top-level windows managed by the OS and it can be used like this (VO code – please don’t mind the style, it’s for minimum line length):
FUNCTION Start() AS INT
EnumWindows(@EnumWindowsCallback() , 0)
WAIT
RETURN 0
// this is the callback function:
FUNCTION EnumWindowsCallback(hWnd AS PTR , lParam AS INT) AS LOGIC
LOCAL pszString := MemAlloc(100) AS PSZ
IF GetWindowText(hWnd,pszString,100) != 0
? pszString
ENDIF
MemFree(pszString)
RETURN TRUE
There are a lot of such callback functions used in the VOSDK and in a lot of VO-programmers’ code as well. And this code can work in .Net, too, but unfortunately not without some changes, because the calling convention of the function when compiled in .Net is different to what the OS expects. Making those changes (see below) is not too difficult, but the real hard part is to locate those places (possibly among 100,000s of other lines of code) where callbacks are used.
Page 2 of 4